· azure · 8 min read
Setup Docker Swarm Cluster on Ubuntu 18.04 in Azure VPS
Docker Swarm is native clustering for Docker. It turns a pool of Docker hosts into a single, virtual host. We continue to run the Docker commands we’re used to, but now they are executed on a cluster by a swarm manager. The machines in a swarm can be physical or virtual. After joining a swarm, they are referred to as nodes.

If you ever think of setting up your own IT Infrastructure to host required applications, i.e, Website (Corporate or Blog), File Server, Mail Server, Team Collaboration Software, ERP, CRM, Forums, DB Server to host databases for all the applications and many more with low cost and high availability. This post is for you…Let’s start
Introduction
In the olden days, it is very difficult because we need to host our infrastructure on Physical Devices and if something goes wrong, it could take days to recover the applications running on it. There is a possibility of data loss if we don’t have data redundancy. And also it is a very expensive and time-consuming process.
Nowadays, I call them Golden Days or Cloud Era, we can set up / create / install our own IT Infrastructure within Hours with Virtual Machines in Public Cloud or Private Cloud Environment. We can use Raspberry Pi to host Docker Swarm at home.
One of the most popular tools/software for this purpose is Docker Swarm. There are other software’s available. I tried most of them. But Docker Swarm is simple, easy to install and it’s Docker native orchestration tool that integrates easily.
We can scale our Docker Swarm Cluster horizontally (adding more nodes to it) or vertically (scale running applications on it – more replicas) in matter of minutes.
There are many storage software tools available to have our data persistent throughout the Cluster if in case any node goes down, the data should be available on the other nodes, the application should start automatically without impacting the production.
I use GlusterFS as persistent storage tool for my Docker Swarm Cluster.
As a DevOps Engineer I Started learning Docker and other Open Source tools for the purpose. There are so many Open Source tools available for us to explore and choose the right one for our requirement.
I am hosting all of my applications/tools like WordPress, Docker Mail Server, Rocket Chat, Next Cloud, Dolibarr ERP, Metabase, Flarum……etc on Docker Swarm Cluster and thought of sharing the experience with you all. I am using MariaDB as back-end database server for all my applications.
I use Traefik in front of all my applications as a Reverse Proxy or Load Balancer to expose them to out side world. It is the most popular software in Container Era or Micro-Services Era as I say. Check Traefik post to understand and how to deploy it on our Docker Swarm Cluster.
We need to host our Docker Swarm Cluster at home using Raspberry Pi or use any cloud provider to buy VPS servers.
Please use the below referral link if you want to use Digital Ocean to buy VPS servers to host your infrastructure.
https://m.do.co/c/4fc5bb284d41
Now let’s start our actual topic…
Basics of Docker
What is Docker and Container?
Docker is a set of platform as a service (PaaS) that uses OS-level virtualization to deliver software in packages called Containers. A container is a standard unit of software, they are isolated from one another and bundle their own software, libraries, and configuration files. All containers are run by a single operating system kernel and are more lightweight than virtual machines.
The software that hosts the containers is called Docker Engine. It was first started in 2013 and is developed by Docker, Inc
If you want to know/learn more about Containers, how they are different from virtual machines, and their uses, I will write a separate article to explain the technology.
For the time being, go through Wikipedia and Docker links to know about container technology.
Basics of Docker Swarm
Docker Swarm is native clustering for Docker. It turns a pool of Docker hosts into a single, virtual host. We continue to run the Docker commands we’re used to, but now they are executed on a cluster by a swarm manager. The machines in a swarm can be physical or virtual. After joining a swarm, they are referred to as nodes.
Swarm managers are the only machines in a swarm that can execute your commands, or authorize other machines to join the swarm as workers.
Workers are just there to provide capacity and do not have the authority to tell any other machine what it can and cannot do.
I am going to build 3 Ubuntu VM’s (1 Manager and 2 worker nodes) in Azure for this purpose. In order to spin the VM’s, you need to have a test account in Azure or you can create a real account to host the Docker Swarm Cluster for hosting your infrastructure there.
I am not going to show you how to build servers in Azure, the process is straight forward and you can find a lot of KB’s for the purpose.
We have to add below docker ports to the VM’s for proper communication between the manager node and worker nodes.
2376/tcp
7946/tcp
7946/udp
2377/tcp
4789/udp
Ports 80/http and 443/https are used for exposing the docker stacks / services to outside world.
After building the VM’s in Azure, SSH to them with the credentials or SSH Key to proceed further.
Prepare Ubuntu 18.04 VM’s
First, add the GPG key for the official Docker repository to the system
sudo curl -fsSL <a href="https://download.docker.com/linux/ubuntu/gpg">https://download.docker.com/linux/ubuntu/gpg</a> | sudo apt-key addAdd the Docker repository to APT sources
sudo add-apt-repository "deb [arch=amd64] <a href="https://download.docker.com/linux/ubuntu">https://download.docker.com/linux/ubuntu</a> $(lsb_release -cs) stableNext, update the package database with the Docker packages from the newly added repo
sudo apt-get updateInstall Docker
Let’s start installing Docker on the VM’s. Run the below command on all the VM’s to install Docker.
sudo apt-get install -y docker-ceDocker should now be installed, the daemon started, and the process enabled to start on boot. Check the version using docker –v the command
![]()
Docker Version
You can check the status by running the below command
sudo systemctl status dockerInstalling Docker now gives you not just the Docker service (daemon) but also the docker command-line utility, or the Docker client.
Install Docker Compose
Now it’s time to install Docker Compose on the VM’s.
Check the current release and if necessary, update it in the command below
sudo curl -o /usr/local/bin/docker-compose -L "https://github.com/docker/compose/releases/download/1.28.5/docker-compose-$(uname -s)-$(uname -m)"Next set the permissions for docker-compose
sudo chmod +x /usr/local/bin/docker-composeThen verify the installation was successful by checking the version:
Check the version by using docker-compose –v command
![]()
Docker Compose Version
Initialize Docker Swarm
Now it’s time to initiate our docker swarm cluster using the below command.
docker swarm initThe above command will make the node as Master in Swarm Cluster and you will see the below output
Swarm initialized: current node (85s5e41x55jyx3oflte9qdo5p) is now a manager
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-0eith07xkcg93lzftuhjmxaxwfa6mbkjsmjzb3d3sx9cobc2zp-97s6xzdt27y2gk3kpm0cgo6y2If you want to advertise swarm to a specific IP, you have to append the IP using
--advertise-addr 192.168.0.7todocker swarm initcommand
Run the docker swarm join command we got from docker init on the worker nodes to join them to the swarm cluster
docker swarm join --token SWMTKN-1-0eith07xkcg93lzftuhjmxaxwfa6mbkjsmjzb3d3sx9cobc2zp-97s6xzdt27y2gk3kpm0cgo6y2From the manager node, ensure that the nodes are checked in by running docker node ls command and you will see the below output

Docker Nodes
Install GlusterFS
Now it’s time to install Replicated GlusterFS Volume on the swarm cluster for data persistent purpose
You have to add below GlusterFS ports to the VM’s in Azure to have data replicated throughout the cluster if I would like to have some persistent data.
The brick ports have changed since version 3.4.
24007 – Gluster Daemon
24008 – Management
24009 and greater (GlusterFS versions less than 3.4) OR
49152 (GlusterFS versions 3.4 and later) – Each brick for every volume on your host requires it’s own port. For every new brick, one new port will be used starting at 24009 for GlusterFS versions below 3.4 and 49152 for version 3.4 and above. If you have one volume with two bricks, you will need to open 24009 – 24010 (or 49152 – 49153).
38465 – 38467 – this is required if you by the Gluster NFS service.
The following ports are TCP and UDP:
- 111 – portmapper
Install software-properties-common
sudo apt-get install software-properties-commonAdd the community GlusterFS PPA
sudo add-apt-repository ppa:gluster/glusterfs-7Update the servers
sudo apt-get updateFinally, Install GlusterFS Server
sudo apt-get install glusterfs-serverStart the glusterd service and enable it to launch every time at system boot
sudo systemctl start glusterdsudo systemctl enable glusterdProbe the worker node from the manager node
sudo gluster peer probe node1
peer probe: successNote: If you have more than one node, you have to probe the other nodes as well.
sudo gluster peer probe node2
peer probe: successView GlusterFS pool list
sudo gluster pool list
GlusterFS Pool List
Create the file directory where GlusterFS will store the data for the bricks that we will specify when creating the volume. Below code needs to be run on all the nodes in the cluster.
sudo mkdir -p /gluster/brickCreate glusterfs replicated volume
sudo gluster volume create swarm-gfs replica 2 manager:/gluster/brick node1:/gluster/brick forceNote: If you have more than one worker node, you have to use the below command. (Replace manager and worker nodes with your actual VM names)
sudo gluster volume create swarm-gfs replica 3 manager:/gluster/brick node1:/gluster/brick node2:/gluster/brick forceYou will see the below output
volume create: swarm-gfs: success: please start the volume to access dataNow start the above-created volume
sudo gluster volume start swarm-gfs
volume start: swarm-gfs: successVerify the GlusterFS Volume by running the below command on the Manager node
sudo gluster volume info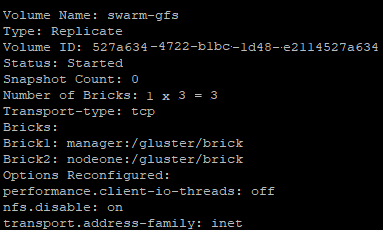
GlusterFS Replicated Volume Info
It’s time to mount the GlusterFS replicated volume on each Node in the swarm cluster on /mnt by running the below commands.
sudo umount /mnt
sudo chown -R USERNAME /etc/fstab /mnt
sudo chown -R USERNAME /mnt
sudo echo 'localhost:/swarm-gfs /mnt glusterfs defaults,_netdev,backupvolfile-server=localhost 0 0' -- /etc/fstab
sudo mount.glusterfs localhost:/swarm-gfs /mnt
sudo chown -R USERNAME:docker /mntNote: Run the above command on all nodes including the manager. Don’t forget to replace USERNAME.
Volume will be mounted on all the nodes, and when a file is written to the
/mntpartition, data will be replicated to all the nodes in the Cluster.
Please watch the below video for the Docker Swarm setup
Please watch the below video for GlusterFS Replicated Volume setup in Docker Swarm
In the coming posts, I will show you how to run stacks/services to the Swarm Cluster with a reverse proxy (Traefik) and SSL (Letsencrypt) enabled by default. Stay tuned… 🙂